
※ t검정 정의 및 기본가정
t검정은 두 집단 이하의 평균을 비교하는 분석방법으로 모집단의 분산을 알지 못할 때 사용하며, 기본 가정은 다음과 같다.
• 종속변수가 양적 변수이어야 한다.
• 모집단의 분산, 표준편차를 알지 못할 때 사용한다.
• 모집단 분포가 정규분포이어야 한다.
• 등분산 가정이 충족되어야 한다.
만약, 모집단의 분포가 정규분포라는 가정을 충족시키지 못하면 비모수 통계(nonparametric statistics)를 사용하여야 한다. 또한 두 집단의 분산이 같지 않아 등분산 가정을 충족시키지 못할 경우에는 두 독립 표본 t검정 대신에 Welch-Aspin 검정을 사용하여야 한다.
1. 단일 표본 t검정(one-samplet test)
단일 표본 검정이란 모집단의 분산을 알지 못할 때 모집단에서 추출된 표본의 평균과 연구자가 이론적 배경이나 경험적 배경에 의하여 설정한 특정한 수를 비교하는 방법이다. 실제 연구에서는 모집단의 분산을 알지 못하므로 단일 표본 검정을 자주 사용한다.
예를 들어, 어떤 연구자가 새로운 교수법을 개발하여 중학교 3학년 학생에게 수업을 실시한 후 그 학생들의 수학 점수 평균이 경험적 배경에 의하여 설정한 중학교 3학년 학생들의 평균이라 생각하는 68점과 같은지를 알아보는 경우다. 즉, 새로운 교수법이 효과가 있는지 없는지를 검정하기 위하여 중학교 3학년을 대표할 수 있는 표본을 추출하여 새로운 교수법을 실시한 후 그 표본에서 얻은 평균과 표준편차를 가지고 검정하는 방법이다.
* 단일 표본 t검정 SPSS에서 분석하기
1) 분석 -> 평균 비교 -> 일 표본 T검정

2) 단일 표본 t검정 수행하고자 하는 변수 선택하여 검정 변수로 옮기고, 검정하고자 하는 대상 값을 검정 값에 입력한다

3) 옵션: 신뢰구간, 결측 값 선택(디폴트 값으로 주로 사용함) 후 확인
4) 분석 결과 해석

유의 확률이 p<.001이므로 검정 변수는 검정 값과 같지 않다고 결론 내릴 수 있다. 예를 들어, 우리나라 중학교 2학년 과학 성취도 평균이 470점과 같은지 알아보기 위해 단일 표본 t검정을 수행한 결과 유의확률은 .000으로 유의수준 .001에서 우리나라 학생들의 과학 성취도 평균은 470점은 아니다라고 결론 내릴 수 있다.
2. 두 종속(대응) 표본 t검정(two-dependent samplest test; matched pair t test)
두 종속(대응) 표본 검정은 종속변수가 양적 변수고, 두 집단이 독립적이지 않을 경우 두 집단의 종속변수에 대한 차이 연구를 위하여 사용하는 통계적 방법으로, 행동과학을 위한 연구에서 자주 사용된다. 두 집단이 종속적이라는 것은 추출된 표본의 모집단들이 서로 관계가 있음을 뜻한다.
대표적인 예로 남녀 비교의 경우 남녀 표본을 남녀 모집단에서 독립적으로 추출하는 것이 아니라 부부 모집단이나 남매 모집단에서 추출하는 경우를 들 수 있다. 이때 남녀 표본은 서로 관계를 가지고 있으며 두 모집단 역시 관계가 있다. 또 다른 예는 사전-사후검사다. 사전검사를 실시하고 난 후 어떤 처치를 가하고 처치 효과가 있는지를 검정하기 위하여 사후검사를 실시하였을 때 사후검사에서 연구대상에 어떤 변화가 나타났다면 이는 처치 효과가 있음을 말해 준다.
이때 사전검사 자료와 사후검사 자료는 동일한 연구대상에게 검사를 두 번 실시하여 얻은 자료이기 때문에 서로 독립적이지 않으며 서로 종속되어 있다. 이런 경우의 자료를 짝지어진 자료(matched pair data)라고도 한다.
* 대응표본 t검정 SPSS에서 분석하기
예) 체력증진을 위해 개발된 새로운 프로그램을 고등학교 2학년 학생 150명을 대상으로 한 학기 동안 적용하였다. 체력증진 프로그램을 적용하기 전후의 학생들의 체력에 차이가 있는가?
1) 분석 -> 평균 비교 -> 대응표본 T검정

2) 대응 변수 두 가지를 변수 1, 변수 2에 각각 삽입한 후, 확인을 클릭한다.

3) 옵션: 신뢰구간, 결측 값 선택(디폴트 값으로 주로 사용함) 후 확인
4) 분석 결과 해석

사전 체력과 사후 체력 간의 차이에 대한 통계적 유의성을 검정한 결과, t=-2.94 유의 확률은 .004로서 유의 수준 .05에서 체력증진 프로그램에 의한 학생들의 사전과 사후의 체력에 차이가 있는 것으로 분석되었다.
3. 두 독립 표본 t검정(two-independent samples test)
두 독립 표본 t 검정이란 각기 다른 두 모집단의 속성인 평균을 비교하기 위하여 두 모집단을 대표하는 표본들을 독립적으로 추출하여 표본 평균을 비교함으로써 모집단 간의 유사성을 검정하는 방법이다. 두 독립 표본 t 검정은 두 표본 집단의 등분 산성을 기본 가정으로 한다.
그러므로 두 독립 표본 검정 전에 두 집단의 분산이 동일한지 확인해야 한다. 연구에서 사용되는 척도가 서열 척도라도 서열 척도 점수의 합이 종속변수면 양적 변수로 간주할 수 있으므로 두 독립 표본 검정을 사용할 수 있다. 그러나 종속변수가 질적 변수일 경우에는 검정을 사용하지 않는다.
* 독립 표본 t검정 SPSS에서 분석하기
예) 성별에 따라 고등학교 2학년 학생들의 외국어 능력에 차이가 있는가?
1) 분석 -> 평균 비교 -> 독립 표본 T검정
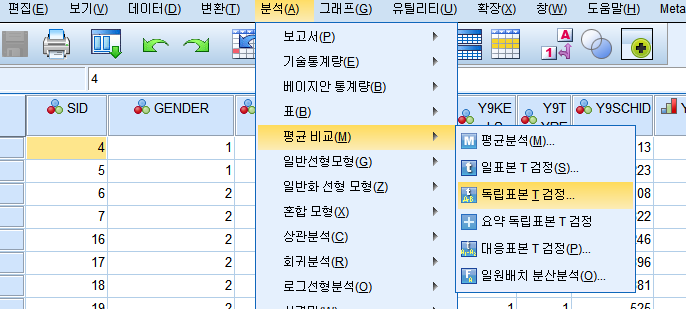
2) 검정 변수에 검정하고자 하는 변수(외국어 점수)를 옮기고 집단 변수에 독립변수(성별)를 선택한다.
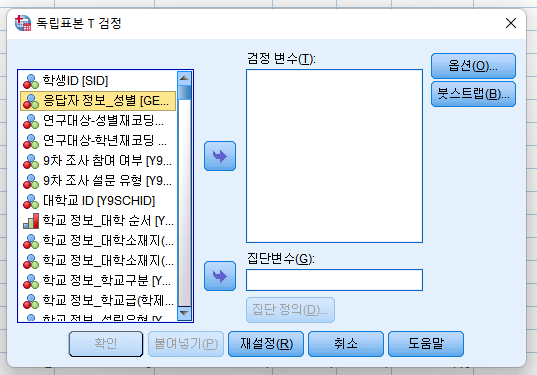
3) 집단 정의 클릭 후, 지정 값 사용에서 집단 1, 집단 2 값을 입력한다. 성별 변수가 남자는 1, 여자는 2로 코딩되어 있는 경우 집단 1 값은 1, 집단 2 값은 2로 입력한다.
(* 절단점: 독립변수가 2개 이상 범주로 되어 있는 경우, 원자료를 두 집단으로 구분해야 하면 절단점을 활용할 수 있다. 예를 들어 대도시, 중소도시, 읍면지역을 각각 1, 2, 3으로 코딩한 경우 세 집단을 두 집단(도시지역, 읍면지역)으로 나누어 두 집단 차이로 검정하려면 절단점 3으로 선택하여 3 미만은 집단 1,2와 3 이상의 집단 3의 두 그룹으로 분리한다)
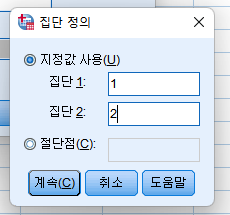
4) 신뢰구간, 결측 값 선택(디폴트 값으로 주로 사용함) 후 확인
5) 분석 결과 해석
Levene의 등분산 검정 결과 유의확률 .282로 두 집단의 분산이 같다는 영가설을 기각하지 않으므로, 외국어 점수에 대한 성별에 따른 등분산 가정이 충족된다. 따라서 두 독립 표본 t검정에서 등분산이 가정되는 부분에서 t통계값과 유의 확률을 가지고 결과를 해석할 수 있다.

남녀 학생들의 외국어 능력에 차이가 있는지에 대한 t통계값은 -2.14, 유의확률 .034로 유의수준 .05에서 성별에 따라 외국어 능력에 유의한 차이가 있는 것으로 분석되었다.
출처: 성태제(2008). SPSS/AMOS를 활용한 알기 쉬운 통계분석. pp125~141. 서울: 학지사.
집단비교(Z검정, t검정)
※ 집단 비교(Z검정, t검정) 1. Z검정 모수 통계로 어떤 집단의 특성이 특정 수치와 같은지 혹은 집단 간의 차이가 있는지를 밝히는 통계적 방법이며, 다음과 같은 조건이 충족되어야 한다. 첫째,
dobbyisfreeya.tistory.com
'교육학 > 연구방법' 카테고리의 다른 글
| 일원분산분석(one-way ANOVA) SPSS로 분석하기 (0) | 2022.10.31 |
|---|---|
| 회귀분석(regression) (0) | 2022.07.27 |
| 요인분석(factor analysis) (0) | 2022.07.26 |
| 상관분석(correlation analysis) (0) | 2022.07.25 |
| 분산분석(ANOVA) (0) | 2022.07.19 |